Relacyjne bazy danych to, najprościej mówiąc, uporządkowane zbiory informacji. Można je porównać do cyfrowej biblioteki, w której dane są poukładane w logiczny sposób, co sprawia, że dostęp do nich jest szybki i intuicyjny. To właśnie na nich opiera się działanie niezliczonych systemów, od bankowości internetowej po sklepy online.
Czym tak naprawdę są bazy danych relacyjne
Pomyśl o wielkiej, perfekcyjnie zorganizowanej bibliotece cyfrowej. Właśnie tym w gruncie rzeczy są bazy danych relacyjne. Choć nazwa brzmi technicznie, zasada ich działania jest zaskakująco prosta i opiera się na logicznych powiązaniach między danymi.
Kluczem do zrozumienia całości jest właśnie analogia do biblioteki. Każdą tabelę w bazie danych można traktować jak osobny regał, na którym trzymamy konkretny rodzaj informacji �– na przykład jeden regał z danymi klientów, a drugi z informacjami o produktach.
Jak to działa w praktyce?
W takiej strukturze każdy element ma swoje precyzyjnie określone miejsce, co ogromnie ułatwia zarządzanie i odszukiwanie informacji. Spójrzmy na prosty przykład sklepu internetowego:
- Tabela (regał): Przechowuje zbiór powiązanych ze sobą danych, np. tabela
Klienci. - Wiersz (książka na regale): Reprezentuje pojedynczy wpis. Na przykład, w tabeli
Kliencijeden wiersz to wszystkie dane jednego klienta: Jan Kowalski,[email protected], ul. Prosta 1, Warszawa. - Kolumna (kategoria na okładce): Określa konkretny typ informacji dla każdego wpisu w tabeli. W tabeli
Kliencikolumnami będą:Imię,Nazwisko,Email,Ulica,Miasto.
Dzięki takiemu podejściu wszystkie informacje o Janie Kowalskim znajdują się w jednym, łatwym do znalezienia wierszu. Z kolei wszystkie adresy e-mail klientów są zebrane w jednej kolumnie.
Prawdziwa siła relacyjnych baz danych nie tkwi jednak w samych tabelach, ale w relacjach, które je łączą. To właśnie te połączenia pozwalają zadawać skomplikowane pytania i wyciągać z danych wartościowe wnioski.
Dlaczego relacje są kluczowe?
Relacje działają jak niewidzialne nici, które łączą informacje z różnych "regałów". Wracając do naszego przykładu sklepu, możemy połączyć tabelę Klienci z tabelą Zamówienia za pomocą unikalnego identyfikatora klienta (np. ID_Klienta).
Przykład praktyczny: Jan Kowalski (o ID_Klienta = 42) składa zamówienie na dwa produkty. W tabeli Zamówienia powstaje nowy wpis (np. o ID_Zamowienia = 1001), który w specjalnej kolumnie ID_Klienta ma zapisaną wartość 42.
Dzięki temu prostemu zabiegowi możemy błyskawicznie uzyskać odpowiedzi na pytania w stylu: „Pokaż mi wszystkie zamówienia złożone przez Jana Kowalskiego” albo „Które produkty najczęściej kupują klienci z Warszawy?”. Bez relacji musielibyśmy ręcznie przeszukiwać obie tabele, co byłoby nie tylko czasochłonne, ale też narażone na błędy.
Ta logiczna, uporządkowana struktura i możliwość łączenia danych sprawiły, że bazy danych relacyjne stały się fundamentem, na którym zbudowano współczesny cyfrowy świat. Ich dojrzałość, stabilność i standaryzacja przez język SQL doprowadziły do powszechnego zastosowania. Ciekawostką jest, że jeszcze na początku lat 2010. stanowiły one ponad 80% wszystkich wdrożeń baz danych w polskim biznesie i sektorze publicznym.
Oczywiście model relacyjny, choć potężny, nie jest jedynym rozwiązaniem. Jeśli chcesz dowiedzieć się, jak zarządzać danymi, które nie pasują do sztywnych tabel, koniecznie sprawdź nasz artykuł o bazach danych NoSQL.
Jak zbudowana jest relacyjna baza danych
Żeby naprawdę zrozumieć, jak działają relacyjne bazy danych, musimy zajrzeć pod maskę i rozłożyć je na części pierwsze. Na pierwszy rzut oka mogą wydawać się skomplikowane, ale cała ich architektura opiera się na kilku prostych, logicznych zasadach. To one tworzą solidny fundament do przechowywania informacji.
Wyobraźmy sobie zwykły sklep internetowy. Jego baza danych musi w jakiś sensowny sposób gromadzić dane o klientach i ich zamówieniach. W modelu relacyjnym podejdziemy do tego, tworząc dwie osobne tabele: jedną dla klientów, a drugą dla zamówień.
Z czego składa się tabela
Każda tabela w relacyjnej bazie danych to po prostu siatka składająca się z wierszy (nazywanych rekordami) i kolumn (nazywanych atrybutami lub polami). To podstawowe klocki, z których budujemy całą strukturę.
W naszym przykładzie:
- Tabela
Kliencibędzie przechowywać informacje wyłącznie o użytkownikach: ich imiona, nazwiska, adresy itp. - Tabela
Zamówieniabędzie zbierać dane o każdej transakcji w sklepie: numer zamówienia, datę, kwotę.
Dzięki takiemu podziałowi dane są uporządkowane i unikamy ich powielania. Każda tabela ma jasno określone zadanie, co ułatwia zarządzanie i po prostu zapobiega bałaganowi. Poniższa grafika dobrze to ilustruje.
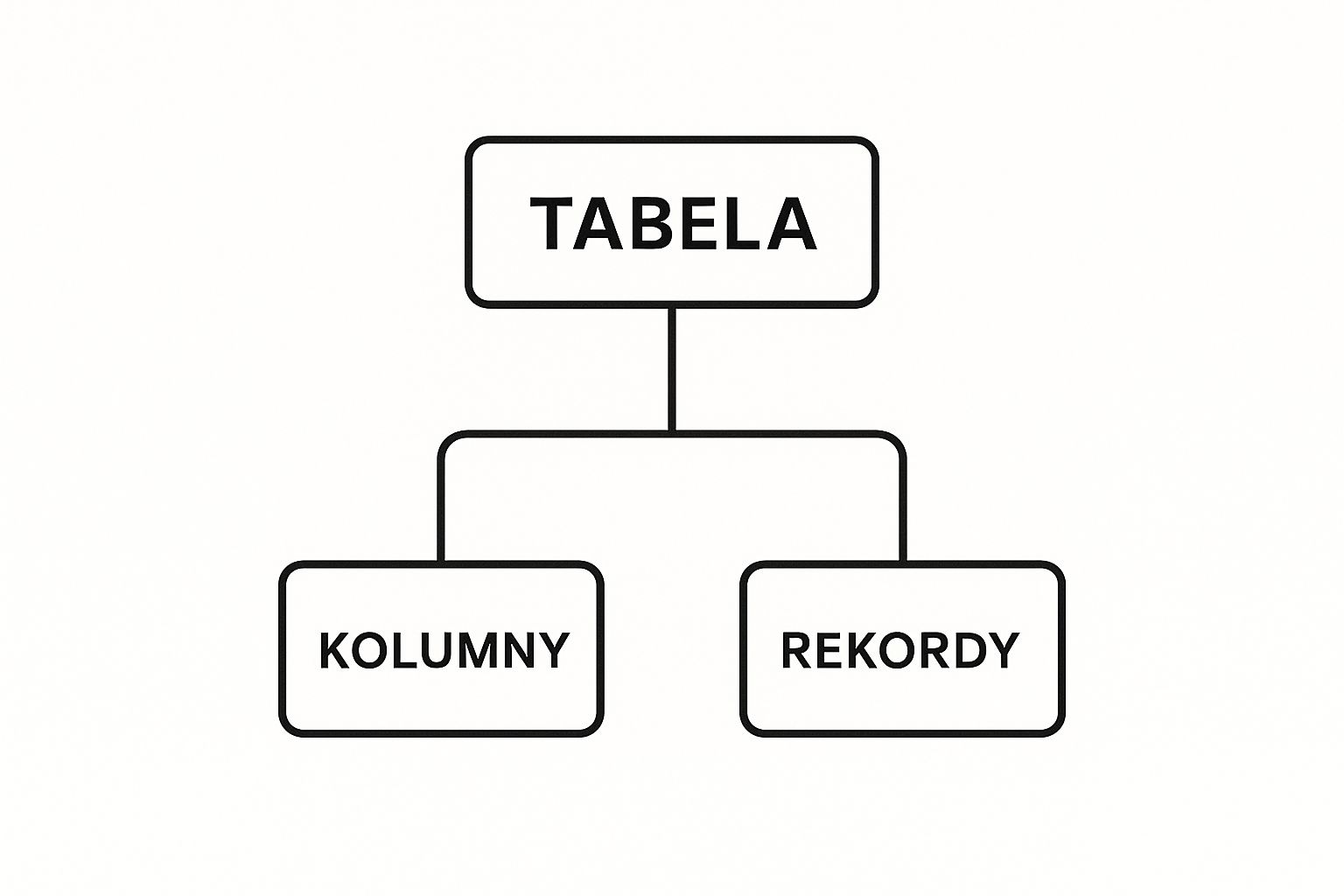
Jak widać, tabela to logiczna całość, gdzie na przecięciu każdego wiersza i kolumny znajduje się pojedyncza informacja.
Zanim pójdziemy dalej, warto zapoznać się z kilkoma kluczowymi pojęciami. Poniższa tabela zbiera najważniejsze terminy i tłumaczy je w prosty sposób.
Kluczowe pojęcia w relacyjnych bazach danych
Zestawienie podstawowych terminów i ich prostych definicji, które pomogą zrozumieć architekturę RDBMS.
| Termin | Analogia | Krótki opis |
|---|---|---|
| Tabela | Arkusz kalkulacyjny | Zbiór powiązanych danych, zorganizowany w wiersze i kolumny. |
| Rekord (Wiersz) | Pojedynczy kontakt w książce adresowej | Jeden kompletny wpis w tabeli, np. dane jednego klienta. |
| Atrybut (Kolumna) | Nagłówek w arkuszu (np. "Imię") | Określony typ informacji dla każdego rekordu w tabeli. |
| Klucz główny | Numer PESEL | Unikalny identyfikator dla każdego rekordu w tabeli. |
| Klucz obcy | Odnośnik do innego dokumentu | Klucz główny z jednej tabeli umieszczony w innej, aby je połączyć. |
| Relacja | Połączenie między osobami w rodzinie | Związek między danymi w różnych tabelach, tworzony za pomocą kluczy. |
Te podstawowe elementy tworzą spójny i logiczny system, który pozwala na efektywne zarządzanie nawet ogromnymi zbiorami danych.
Klucze, czyli spoiwo łączące dane
Skoro mamy już dwie osobne tabele, to jak połączyć konkretne zamówienie z klientem, który je złożył? I tu właśnie na scenę wchodzą klucze. To one są najważniejszym mechanizmem, który tworzy relacje między danymi.
Klucze działają jak unikalne numery identyfikacyjne. Pozwalają jednoznacznie wskazać konkretny rekord w tabeli, a następnie użyć tego identyfikatora do połączenia go z danymi w innej tabeli.
Mamy dwa podstawowe rodzaje kluczy:
-
Klucz główny (Primary Key): To unikalny identyfikator dla każdego rekordu w danej tabeli. W naszej tabeli
Kliencitakim kluczem będzie na przykładID_Klienta. System pilnuje, aby nigdy nie istniały dwa rekordy o tym samym kluczu głównym, co daje nam gwarancję unikalności każdego wpisu. Można go porównać do numeru PESEL – każdy ma swój i jest on niepowtarzalny. -
Klucz obcy (Foreign Key): To po prostu klucz główny z jednej tabeli, który został "pożyczony" i umieszczony w drugiej, aby stworzyć między nimi połączenie. W tabeli
Zamówieniadodamy więc kolumnęID_Klienta, która będzie właśnie kluczem obcym.
Jak to działa w praktyce?
Załóżmy, że nowy klient, Jan Kowalski, rejestruje się w naszym sklepie. W tabeli Klienci automatycznie powstaje dla niego nowy rekord z unikalnym ID_Klienta, powiedzmy 123.
Kiedy Jan Kowalski składa swoje pierwsze zamówienie, w tabeli Zamówienia również tworzony jest nowy wpis. I teraz najważniejsze: żeby powiązać to zamówienie z Janem, w kolumnie ID_Klienta w tabeli Zamówienia wpisujemy wartość 123.
Dzięki temu prostemu zabiegowi baza danych doskonale "wie", że to zamówienie należy właśnie do niego. Ten mechanizm kluczy jest fundamentem, który sprawia, że relacyjne bazy danych są tak spójne i niezawodne.
Jak „rozmawiać” z bazą danych, czyli podstawy języka SQL

Skoro wiemy już, jak poukładane są relacyjne bazy danych, pora nauczyć się z nimi dogadywać. Do tej „rozmowy” służy nam specjalny język – SQL (Structured Query Language). Ale bez obaw, nie trzeba być programistą, żeby go zrozumieć. SQL bardziej przypomina zestaw prostych, logicznych komend niż skomplikowany kod.
To właśnie SQL jest uniwersalnym sposobem na zadawanie pytań bazie danych i wydawanie jej poleceń. Za jego pomocą możemy poprosić o konkretne informacje, dodać zupełnie nowe dane albo zmodyfikować te, które już istnieją. Cała jego siła tkwi w prostocie i czytelnej składni.
Cztery podstawowe operacje w SQL – fundament pracy z danymi
Właściwie cała codzienna praca z danymi sprowadza się do czterech kluczowych działań, które fachowo określa się skrótem CRUD (od angielskich słów Create, Read, Update, Delete). Każdej z tych operacji odpowiada jedno, podstawowe polecenie w SQL:
- SELECT – Służy do odczytywania danych z tabel. To komenda, której będziesz używać najczęściej.
- INSERT – Pozwala tworzyć (wstawiać) nowe wiersze, czyli rekordy, do tabeli.
- UPDATE – Służy do aktualizowania istniejących już danych.
- DELETE – Umożliwia usuwanie rekordów z tabeli.
Opanowanie tych czterech poleceń to jak zdobycie kluczy do skarbca z danymi. Dają Ci pełną kontrolę nad informacją – możesz precyzyjnie decydować, co się z nią dzieje, zamiast polegać tylko na gotowych przyciskach w jakiejś aplikacji.
Jak to wygląda w praktyce? Konkretne przykłady zapytań
Zobaczmy, jak te polecenia działają w prawdziwym życiu. Wyobraź sobie, że masz tabelę Klienci w bazie swojego sklepu internetowego. Tabela ma kolumny: Imie, Nazwisko, Miasto i Email.
Przykład 1: Wyciąganie danych (SELECT)
Chcesz zobaczyć listę wszystkich klientów z Warszawy. Wystarczy, że „powiesz” bazie:
SELECT Imie, Nazwisko, Email FROM Klienci WHERE Miasto = 'Warszawa';
To polecenie można przetłumaczyć jako: „Hej, bazo! Pokaż mi imię, nazwisko i e-mail wszystkich osób z tabeli Klienci, którzy w kolumnie Miasto mają wpisaną 'Warszawę'”. Proste, prawda?
Przykład 2: Dodawanie nowego rekordu (INSERT)
Teraz do Twojej bazy dołącza nowa osoba. Aby ją dodać, piszesz:
INSERT INTO Klienci (Imie, Nazwisko, Miasto, Email) VALUES ('Anna', 'Nowak', 'Kraków', '[email protected]');
Tym samym dajesz bazie jasny sygnał: „Dodaj nowy wiersz do tabeli Klienci i wypełnij go tymi danymi”.
Przykład 3: Poprawianie danych (UPDATE)
Okazuje się, że Anna Nowak przeprowadziła się do Gdańska. Trzeba zaktualizować jej dane:
UPDATE Klienci SET Miasto = 'Gdańsk' WHERE Email = '[email protected]';
To zapytanie najpierw znajduje wiersz, w którym e-mail to [email protected], a następnie zmienia w nim wartość w kolumnie Miasto na „Gdańsk”.
Przykład 4: Kasowanie danych (DELETE)
A co, jeśli klientka poprosi o usunięcie swojego konta? Użyjesz komendy DELETE:
DELETE FROM Klienci WHERE Email = '[email protected]';
To polecenie bezpowrotnie usunie cały wiersz dotyczący Anny Nowak z Twojej tabeli.
Jak widzisz, podstawy SQL są naprawdę logiczne i intuicyjne. Te proste komendy to fundament, na którym opiera się cała interakcja z relacyjnymi bazami danych. To potężne narzędzie, które oddaje zarządzanie informacją prosto w Twoje ręce.
Praktyczne zastosowania i największe zalety
Mimo że na rynku pojawia się mnóstwo nowych technologii, relacyjne bazy danych wciąż grają pierwsze skrzypce w najważniejszych sektorach gospodarki. Ich popularność to nie przypadek – to efekt kluczowych zalet, które dają biznesowi to, czego potrzebuje najbardziej: przewidywalność, bezpieczeństwo i spójność danych.
Fundamentem tej niezawodności jest integralność danych. Działa to trochę jak mądry strażnik, który pilnuje, by do bazy trafiały tylko poprawne i pasujące do siebie informacje. Mechanizmy te nie pozwolą na przykład przypisać zamówienia do klienta, który nie istnieje w systemie, albo wpisać daty urodzenia w formacie "słownym". Taka wbudowana dyscyplina sprawia, że dane stają się wiarygodnym źródłem prawdy dla całej firmy.
Gwarancja niezawodności, czyli transakcje ACID
Kolejnym potężnym atutem jest obsługa transakcji opartych na modelu ACID (Atomicity, Consistency, Isolation, Durability). To po prostu zestaw czterech żelaznych reguł, które pilnują, aby każda operacja na danych była wykonana w całości albo wcale.
Pomyśl o zwykłym przelewie bankowym – to operacja złożona z dwóch kroków: zabrania pieniędzy z jednego konta i dodania ich na drugie.
- Atomowość (Atomicity): Gwarantuje, że oba te kroki wykonają się razem. Jeśli coś pójdzie nie tak w połowie drogi, cała operacja jest anulowana. Pieniądze nie wyparują w próżni.
- Spójność (Consistency): Pilnuje, aby każda transakcja zostawiła bazę w prawidłowym, logicznym stanie.
- Izolacja (Isolation): Sprawia, że dwie operacje wykonywane w tym samym czasie nie przeszkadzają sobie nawzajem. To dzięki niej dwie osoby nie mogą w tej samej sekundzie zarezerwować tego samego miejsca w kinie.
- Trwałość (Durability): Zapewnia, że gdy transakcja zostanie zatwierdzona, jej wynik jest zapisany na stałe i przetrwa nawet awarię systemu.
To właśnie właściwości ACID sprawiają, że relacyjne bazy danych są fundamentem systemów, gdzie najmniejszy błąd może kosztować realne pieniądze lub zaufanie klientów.
Gdzie bazy relacyjne sprawdzają się najlepiej?
Dzięki swojej solidnej strukturze i niezawodności, relacyjne bazy danych są po prostu niezastąpione w wielu obszarach. Ich historia sięga lat 70., kiedy Edgar Codd wpadł na pomysł modelu relacyjnego, a pierwszy komercyjny system wypuścił na rynek Oracle w 1979 roku. Ta długa ewolucja pozwoliła dopracować technologię do perfekcji, dzięki czemu stała się ona kręgosłupem dla niezliczonych firm, także w Polsce. Jeśli chcesz zgłębić temat, dowiedz się więcej o historii i rozwoju tej technologii w Polsce.
Oto kilka przykładów z życia wziętych:
- Systemy finansowe i bankowe: Obsługa kont, kredytów, przelewów i transakcji giełdowych wymaga chirurgicznej precyzji, a tę gwarantuje właśnie model ACID. Praktyczny przykład: Bank Millennium używa systemu opartego na Oracle Database do zarządzania milionami operacji bankowych każdego dnia.
- Platformy e-commerce: Zarządzanie produktami, stanami magazynowymi, zamówieniami i historią zakupów opiera się na logicznych powiązaniach między danymi. Praktyczny przykład: Allegro, choć korzysta z wielu technologii, w swoich kluczowych systemach transakcyjnych opiera się na relacyjnych bazach danych.
- Systemy rezerwacji: Linie lotnicze, hotele czy kina używają ich do zarządzania dostępnością miejsc w czasie rzeczywistym. To one zapobiegają sytuacjom, w których dwa bilety sprzedawane są na to samo miejsce. Praktyczny przykład: System rezerwacyjny LOT-u musi w ułamku sekundy sprawdzać dostępność miejsc i przetwarzać płatności w sposób absolutnie niezawodny.
- Systemy CRM: Przechowywanie danych o klientach, historii rozmów czy statusach sprzedaży wymaga uporządkowanej struktury, którą tabele zapewniają idealnie. W takich systemach kluczowe jest też sprawne łączenie danych, co można osiągnąć np. przez integracje. Przeczytaj więcej o tym, czym są konektory API i jak pomagają one w komunikacji między systemami.
Tworzymy pierwszą relacyjną bazę danych krok po kroku
Teoria jest ważna, ale nic tak nie uczy, jak praktyka. Czas więc zakasać rękawy i przejść od koncepcji do konkretów. Zbudujemy razem prostą, ale w pełni działającą, relacyjną bazę danych dla małego bloga. To świetne ćwiczenie, które pokaże Ci w praktyce, jak logicznie poukładać dane i sprawić, by wszystkie elementy układanki do siebie pasowały.
Nasza baza będzie opierać się na dwóch kluczowych tabelach: jednej dla autorów i drugiej dla wpisów na blogu. Taki podział to fundament myślenia relacyjnego – dzięki niemu unikamy bałaganu i powtarzania tych samych informacji w nieskończoność.
Krok 1: Najpierw plan, czyli projektujemy strukturę
Zanim napiszemy choćby jedną linijkę kodu, musimy mieć solidny plan. To absolutnie najważniejszy etap. Dobrze zaprojektowana struktura to gwarancja, że baza będzie szybka, a praca z nią – przyjemna.
Oto nasz pomysł:
-
Tabela
Autorzy: Tutaj będziemy trzymać informacje o osobach, które piszą artykuły.id_autora– unikalny numer dla każdego autora (to będzie nasz klucz główny).imie– po prostu imię autora.email– adres e-mail do kontaktu.
-
Tabela
Wpisy: W tej tabeli znajdą się wszystkie artykuły.id_wpisu– unikalny identyfikator każdego wpisu (jego klucz główny).tytul– tytuł artykułu.tresc– właściwa treść posta.id_autora– numer identyfikacyjny autora z tabeliAutorzy(nasz klucz obcy).
Zwróć uwagę na kolumnę id_autora w tabeli Wpisy. Działa ona jak most, który łączy każdy artykuł z konkretnym autorem. Proste i genialne.
Krok 2: Czas na kod, czyli tworzymy tabele w SQL
Mamy już plan, więc możemy powołać nasze tabele do życia za pomocą języka SQL. Użyjemy do tego polecenia CREATE TABLE.
Swoją drogą, jeśli podoba Ci się takie logiczne podejście do rozwiązywania problemów, zerknij na nasz przewodnik Python dla początkujących. Tam również krok po kroku wprowadzamy w świat programistycznego myślenia.
CREATE TABLE Autorzy ( id_autora INT PRIMARY KEY, imie VARCHAR(100), email VARCHAR(100) ); CREATE TABLE Wpisy ( id_wpisu INT PRIMARY KEY, tytul VARCHAR(255), tresc TEXT, id_autora INT, FOREIGN KEY (id_autora) REFERENCES Autorzy(id_autora) );
Ten fragment: FOREIGN KEY (id_autora) REFERENCES Autorzy(id_autora) to formalna instrukcja dla bazy danych. Mówimy jej wprost: „Hej, ta kolumna w tabeli Wpisy musi odpowiadać istniejącemu id_autora w tabeli Autorzy”.
Ten prosty mechanizm kluczy to całe serce relacyjnych baz danych. Dzięki niemu mamy pewność, że nie da się dodać wpisu od autora, który nie istnieje. To nasz strażnik spójności danych.
Krok 3: Wypełniamy tabele danymi
Nasza struktura jest gotowa, ale pusta. Wypełnijmy ją przykładowymi danymi, używając polecenia INSERT INTO.
INSERT INTO Autorzy (id_autora, imie, email) VALUES (1, 'Jan Kowalski', '[email protected]'), (2, 'Anna Nowak', '[email protected]'); INSERT INTO Wpisy (id_wpisu, tytul, tresc, id_autora) VALUES (101, 'Wprowadzenie do SQL', 'Treść artykułu o SQL...', 1), (102, 'Bazy relacyjne w praktyce', 'Treść artykułu o RDBMS...', 2), (103, 'Zaawansowane zapytania', 'Treść kolejnego artykułu...', 1);
Krok 4: Magia relacji, czyli łączymy dane
Wszystkie dane są już na swoich miejscach, ale w dwóch osobnych tabelach. Czas zobaczyć, jak pięknie ze sobą współpracują. Użyjemy zapytania z klauzulą JOIN, aby połączyć informacje i wyświetlić listę artykułów razem z imionami ich autorów.
SELECT Wpisy.tytul, Autorzy.imie FROM Wpisy JOIN Autorzy ON Wpisy.id_autora = Autorzy.id_autora;
Co to zapytanie właściwie robi? Mówi bazie: „Pokaż mi tytuły z tabeli Wpisy i imiona z tabeli Autorzy, ale połącz je tak, żeby id_autora zgadzało się w obu miejscach”.
Efekt? Czytelna, połączona lista, która udowadnia, że nasza relacyjna struktura nie tylko ma sens, ale po prostu działa. Proste, prawda?
Masz pytania? Odpowiadamy!
Zebraliśmy tutaj odpowiedzi na kilka pytań, które często pojawiają się przy temacie relacyjnych baz danych. Chcemy w prosty sposób rozwiać wątpliwości i pomóc Ci lepiej zrozumieć, o co w tym wszystkim chodzi.
Czym tak naprawdę różni się baza relacyjna od NoSQL?
Wyobraź sobie, że relacyjna baza danych to precyzyjnie zaprojektowany arkusz kalkulacyjny. Wszystko ma swoje miejsce w tabelach, kolumnach i wierszach. Ta sztywna struktura to jej największa zaleta – zapewnia, że dane są zawsze spójne i uporządkowane. Dlatego banki czy systemy rezerwacji tak ch�ętnie z niej korzystają.
Z kolei bazy NoSQL (czyli Not Only SQL) to bardziej cyfrowy notatnik. Możesz w nim przechowywać dane w różnych formach: jako dokumenty tekstowe, listy punktowane, a nawet grafy powiązań. Ta elastyczność jest bezcenna, gdy pracujesz z ogromną ilością danych o zmiennej strukturze, jak posty i komentarze w mediach społecznościowych.
W skrócie: Potrzebujesz żelaznej dyscypliny i spójności danych? Wybierz model relacyjny. Stawiasz na elastyczność i radzenie sobie z chaosem? NoSQL będzie lepszym wyborem.
Czy muszę umieć programować, żeby korzystać z relacyjnych baz danych?
Absolutnie nie! Oczywiście, tworzenie i zarządzanie skomplikowanymi bazami to praca dla specjalistów, ale wyciąganie z nich informacji jest znacznie prostsze, niż mogłoby się wydawać.
Podstawy języka SQL są naprawdę intuicyjne. Dzięki nim analityk, marketingowiec czy menedżer produktu może samodzielnie zadać bazie pytanie i dostać odpowiedź. Nie trzeba za każdym razem prosić o pomoc działu IT.
Przykład z życia wzięty: Analityk marketingowy w firmie odzieżowej może napisać proste zapytanie SQL, aby dowiedzieć się, które produkty (np. czerwone sukienki w rozmiarze M) sprzedawały się najlepiej w ostatnim kwartale. To zaledwie kilka linijek kodu, a daje potężną wiedzę do ręki.
Kiedy relacyjna baza danych to zły pomysł?
Choć bazy relacyjne są niezwykle użyteczne, nie są lekiem na wszystko. Czasem ich największa zaleta – sztywna struktura – staje się kulą u nogi. Dzieje si�ę tak zwłaszcza w świecie Big Data, gdzie dane są nieprzewidywalne i napływają w ogromnych ilościach.
Oto kilka sytuacji, w których lepiej poszukać innego rozwiązania:
- Aplikacje internetu rzeczy (IoT): Czujniki i urządzenia generują masę danych w różnych formatach. Wciskanie ich na siłę w tabelki byłoby koszmarem. Przykład: Inteligentny dom wysyła dane z czujnika temperatury, licznika prądu i kamery jednocześnie – każdy z tych sygnałów ma zupełnie inną strukturę.
- Złożone katalogi produktów: Gdy jeden produkt ma „rozmiar”, a inny „pojemność baterii”, elastyczność NoSQL pozwala łatwiej zarządzać takimi unikalnymi cechami. Przykład: Sklep z elektroniką sprzedaje laptopy (z parametrami jak RAM, procesor) i słuchawki (z parametrami jak impedancja, pasmo przenoszenia). W bazie NoSQL każdy produkt może mieć swój własny, unikalny zestaw atrybutów.
- Analiza powiązań: Jeśli chcesz analizować sieci znajomych na portalu społecznościowym, grafowe bazy danych zrobią to o wiele sprawniej. Przykład: Facebook czy LinkedIn, aby szybko pokazać Ci "wspólnych znajomych", używają baz grafowych, które są zoptymalizowane do śledzenia takich właśnie połączeń.
W takich przypadkach sztywny schemat relacyjny zamiast pomagać, zaczyna ograniczać, co odbija się na wydajności i skalowalności systemu.
Zarządzaj danymi klientów efektywniej i nie trać żadnej okazji do rozmowy. Voicetta automatyzuje komunikację i integruje się z Twoimi systemami, zapewniając obsługę klienta 24/7. Dowiedz się więcej na https://voicetta.com.